The Linear Entity Segmentation Algorithm
In the infrastructure asset management space, the need for a project to use segmented linear referenced records can arise. This segmentation can be required to support various business, operational or reporting purposes.
This article looks at the Linear Entity Segmentation Algorithm. Or LESA for short.
LESA solves the data problem of segmenting infrastructure-related things, which are defined and located within the constructs of a linear location reference management system.
What sort of things are we talking about here?
Let's say you have some data about footpaths. Or roads. Or treatment lengths. Or surface water channels. Or essentially anything defined with a measured start and end location. In the context of LESA, these things are the linear entities.
And with those linear entities, you need to segment them into smaller sections. Perhaps this is to create some data analysis lengths, inspection sections, treatment lengths or reference sections.
Of course you don't want to do the segmentation manually. So enter LESA to help get the job done quickly and consistently.
Segmentation with user-defined lengths
LESA will segment a linear entity into sections of a user-defined length that you give it.
For an easy example, let’s consider a road that is 600m long.

And for our hypothetical project, we need to create some analysis extents by breaking this road down into 200m long sections. LESA will do this for you quickly, creating three 200m sections for the road (exploded view below and not to scale);
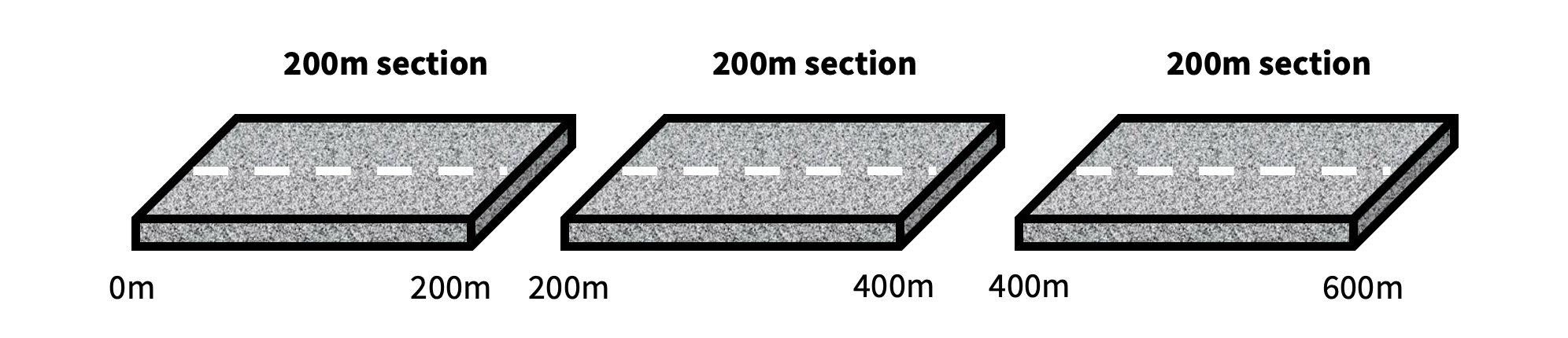
Do those new sections look fit for purpose? If not, you may want to try 400m lengths. To do so, simply rerun the algorithm with a new segment length defined, and you will get back a brand new set of revised sections.
Whether you specify a 1m segment lengths or a 10,000m segment length, LESA will segment linear entities based on the length you require.
What about the segments at the end of the entity?
In the above example, we had a 600m long road. Based on 200m segmentation lengths, the road was neatly segmented into three 200m sections. But real-world data won't always be so clean.
Let's now take a road that is 650m long. And again we will segment it into 200m long sections. We would end up with these four sections;

The final section is 50m long. That is because the last full-length 200m section ended at 600m, leaving 50m remaining for the road. Rather than being ignored, the 50m length became a standalone section on its own.
Now, a 50m section might be reasonable for your needs. But what if things get really short?
Let's consider a road that is 601m long, and we get LESA to return 200m lengths. The output would be something like this (again not to scale);
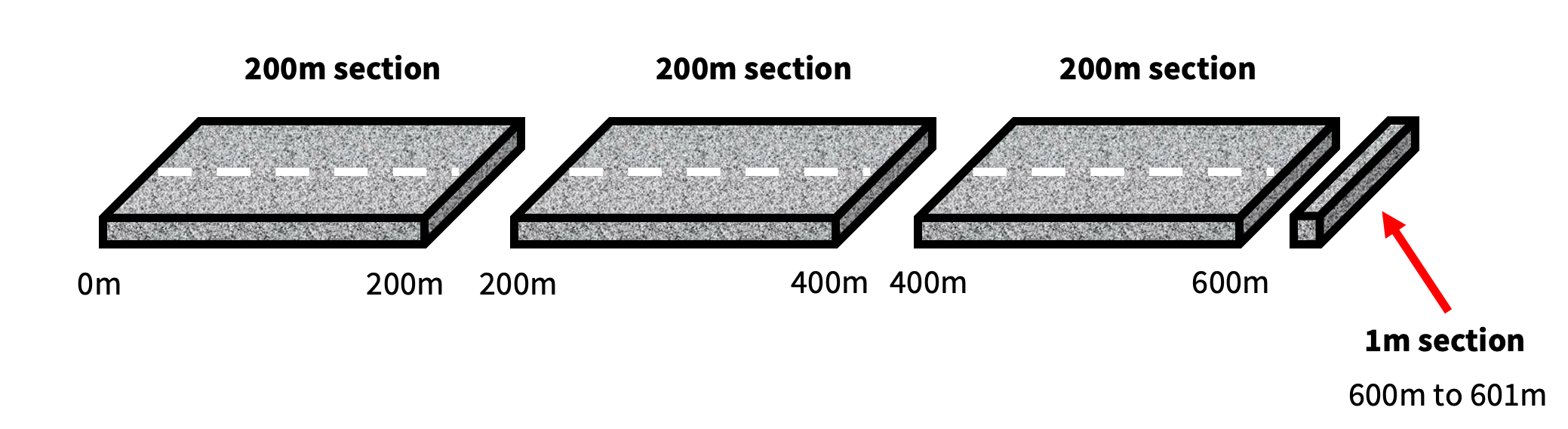
In this scenario, we have ended up with three 200m sections. But we also have a very short 1m section at the end.
Depending on the use case, this may be a less than ideal outcome. So just how short is too short? You can decide with LESA, and there are a few options available.
The final segment buffer
LESA can optionally incorporate a final segment buffer, which folds short lengths into the final section of an entity. While this means the final section can extend above your specified segment length, it comes with the benefit of not having short sections standing on their own at the end.
For instance, you could tell LESA that you want 200m sections. And as part of that segmentation process, you specify the final section for an entity can extend out another 50m.
In the 601m road example above, with a final segment buffer of 50m applied, we would now end up with three sections;
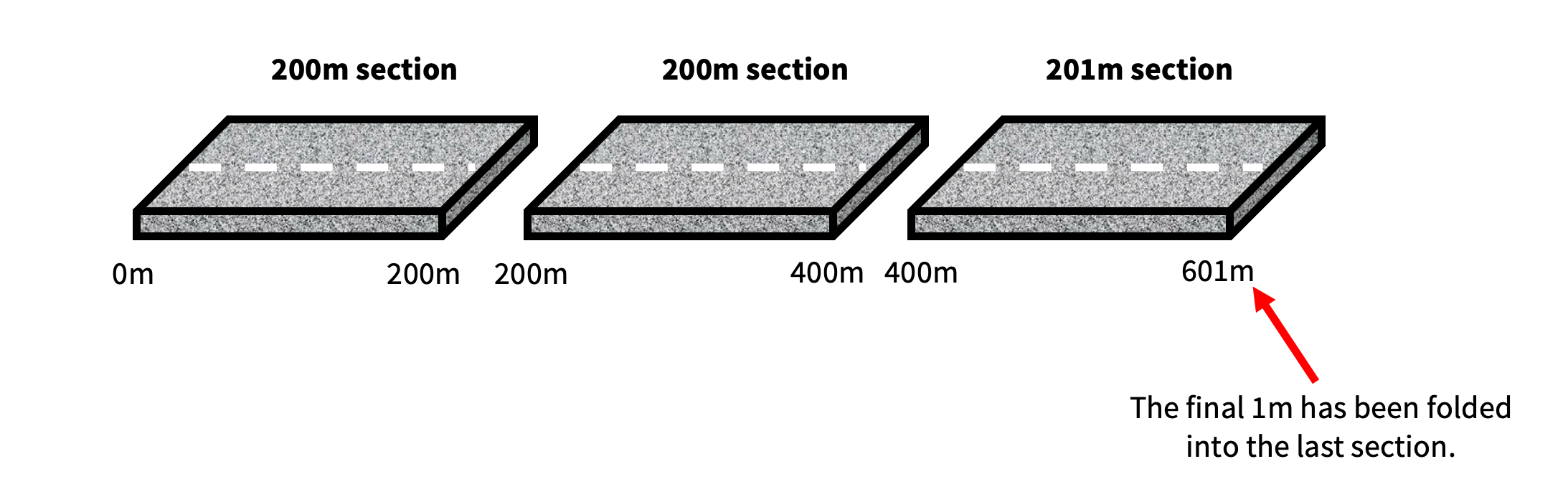
The issue of short lengths is resolved in this output. The final 1m of the road has been bundled into the last section, avoiding any short lengths overhanging at the end.
It is a similar outcomes for a 650m section, where the last section is allowed to extend out a further 50m. This segmentation configuration also produces three sections:
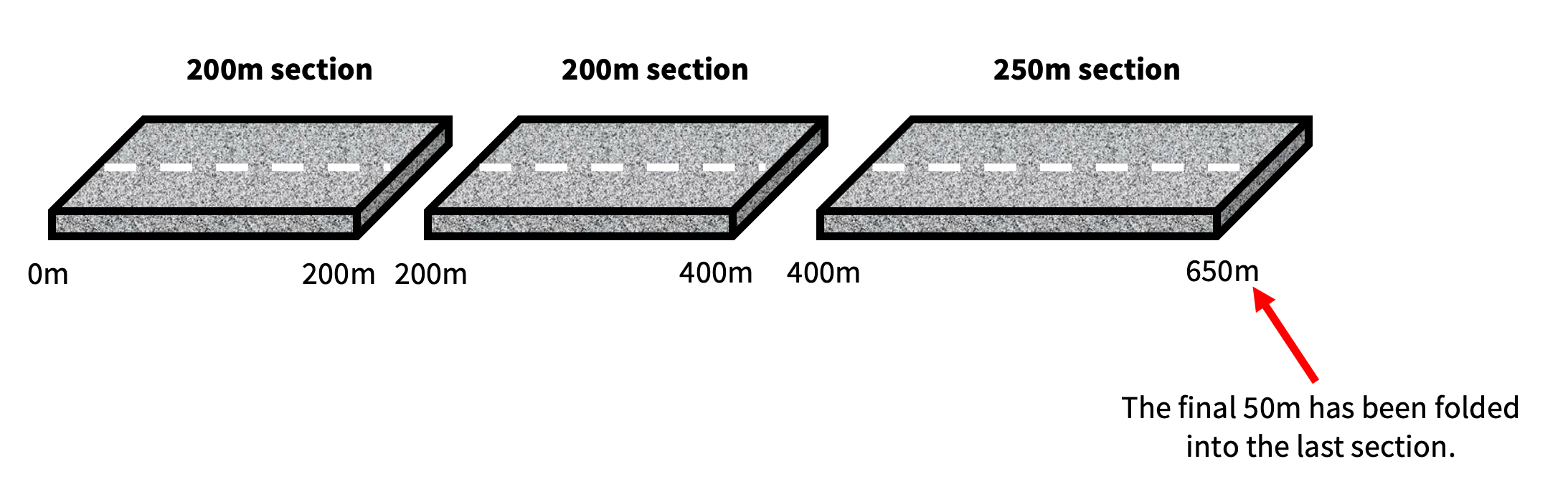
The final section has incorporated the length of road from 400m to 650m. Again solving for any short lengths that potentially could have been left behind.
But what if you don't want a buffer applied? Then, consider specifying a minimum length threshold.
Minimum length thresholds
A minimum length threshold defines the minimum section length that can be considered valid in the algorithm's output.
Let's ignore the final segment buffer for now and take that road that was 601m long. And for this road, we specify a minimum length threshold of 10m. Anything less than that is to be excluded from the results or tagged with a warning. The resulting LESA segmentation would look like this.

We still get the three equally segmented lengths of 200m for the first 600m of the road. But with no final segment buffer, the last 1m of the road is left as a standalone section. And with the minimum length threshold applied, that final 1m section is tagged as being invalid in the outputs.
Minimum length thresholds can become really important when you have linear entities that are shorter than your specified segmentation length. It allows you to work with the shorter length entities in a pragmatic way, enabling what you consider valid to be handled as a valid section, while still proactively managing anything too short to be effective.
Minimum length thresholds and final segment buffers can also be used in conjunction with each other. This can help achieve some very flexible segmentation options depending on the requirements of the project.
Segmenting 800 roads with LESA in under one second
Trying this out with a real-world dataset of 800 roads, LESA was used to create hypothetical 100m analysis sections.
The final segment buffer was set to 40m, meaning the last section for an entity could extend up to 140m, to prevent any short lengths at the end. The minimum segment length threshold was set to 25m.
The resulting segmented dataset contained nearly 18,000 road sections. And these were all consistently created within the specified segmentation constructs - 100m lengths, final sections extending up to 140m, and any sections less than 25m being tagged as invalid.
And the total execution time required by the algorithm to produce this segmentation, was merely a fraction of a second. So this type of segmentation can be done rapidly, even when dealing with datasets containing many linear entities.
That is a wrap on this post about LESA - something I have developed in house here at The Datastack (and am developing - there may be a part two TalkData article about LESA in the future). Often these segmentation challenges are just one element of a broader problem to be solved, and with LESA being available in the toolkit, it provides a flexible option to plug into a potential solution.